Team Members: Dr.M.Krishnaveni , Assistant Professor (SG), Department of Computer Science.
Dr.R.Janani, Research Assistant, CMLI
Ms.A.Hema Priya , II MCA, Department of Computer Science
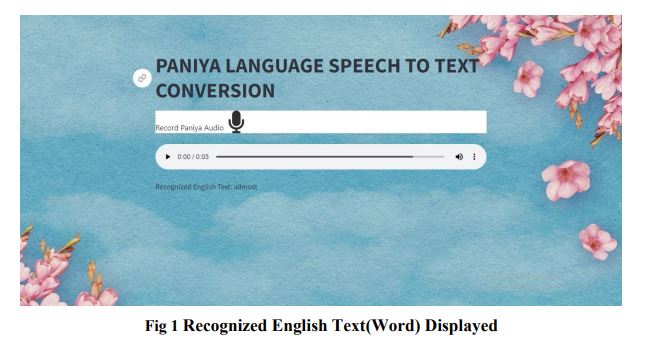
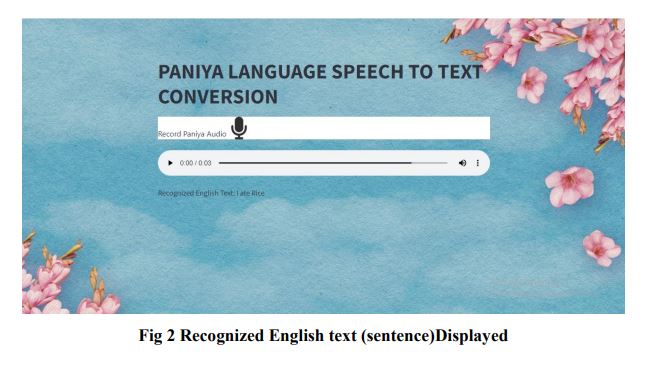
Project Summary:Paniya, also known as Pania, Paniyan, or Panyah, is a tribal language spoken in India, particularly in the Malayalam-speaking regions. The Paniya language people are currently facing a communication barrier with other communities, limiting interactions within their own group. To overcome this issue faced by the Paniya people, a web application has been developed for speech-to-text using deep learning technique. This user-friendly web application aims to provide a convenient platform for individuals to translate Paniya speech into text. The proposed system not only deals with linguistic complexities, of the Paniya language but also ensures accessibility and usability for a wider audience. The software used to develop for this project is python 3 within the collaborative environment Google colab andby using the streamlit library, the web application was developed. To initiate the methodology, a speech dataset consisting of recordings from Paniya speakers has been collected for analysis and processing, followed by pre-processing using spectral subtraction. This technique enhances the signal-to-noise ratio by estimating and subtracting background noise from the audio signal and it ensure the noise free Paniya speech input for subsequent processing. The features are then extracted using the Mel Frequency Cepstral Coefficient (MFCC), which transforms the Paniya speech signal into a concise representation by capturing its spectral characteristics. This enables the Recurrent Neural Network (RNN) to more effectively analyze and comprehend the nuanced phonetic patterns of the language, resulting in more accurate transcription, with this the Convolutional Neural Network (CNN) is also used to determine the accuracy and performance metrics. Moreover, a linguisticdictionary serves as a reference for mapping Paniya language words to their corresponding textual representations. This aids the system in precisely transcribing spoken words and enhances the overall efficiency of the speech-to-text conversion process.